curling down bibtex
When I wrote
the last post
I really wanted to use
curl
to turn rfc
numbers and drafts into
bibtex
entries. I did have a look, but I had other
things to do that seem urgent and I didn't follow it through.
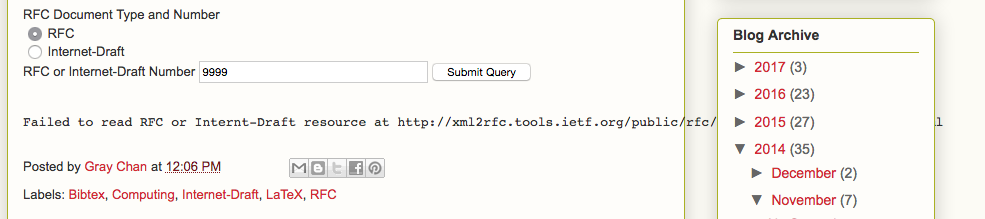
That was lazy of me, the page will generate an error message with a url when
given an rfc or draft that doesn't exist. I looked at this url with a valid
rfc, but it wasn't clear how to turn the returned info into a
bibtex
entry.
Stripping that div off the page makes the url visible:
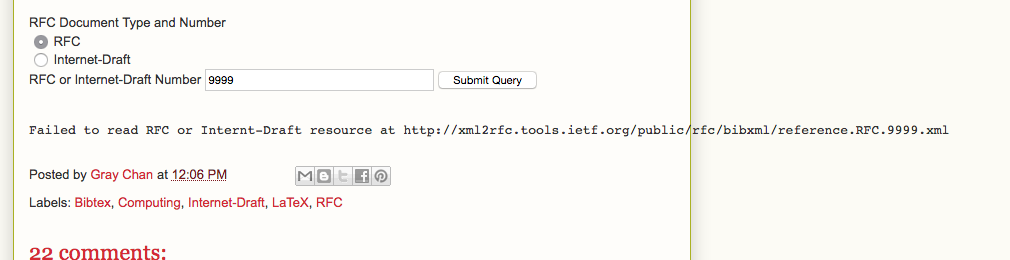
Failed to read RFC or Internt-Draft resource at http://xml2rfc.tools.ietf.org/public/rfc/bibxml/reference.RFC.9999.xml
Using that url format with a valid rfc number (Our beloved RFC768 ) spits out this xml document:
$ curl http://xml2rfc.tools.ietf.org/public/rfc/bibxml/reference.RFC.0768.xml
<?xml version='1.0' encoding='UTF-8'?>
<reference anchor='RFC0768' target='http://www.rfc-editor.org/info/rfc768'>
<front>
<title>User Datagram Protocol</title>
<author initials='J.' surname='Postel' fullname='J. Postel'><organization /></author>
<date year='1980' month='August' />
</front>
<seriesInfo name='STD' value='6'/>
<seriesInfo name='RFC' value='768'/>
<seriesInfo name='DOI' value='10.17487/RFC0768'/>
</reference>
That is how far I got when I gave up earlier. Looking at the page again I thought I might try looking at the network traffic it generates.
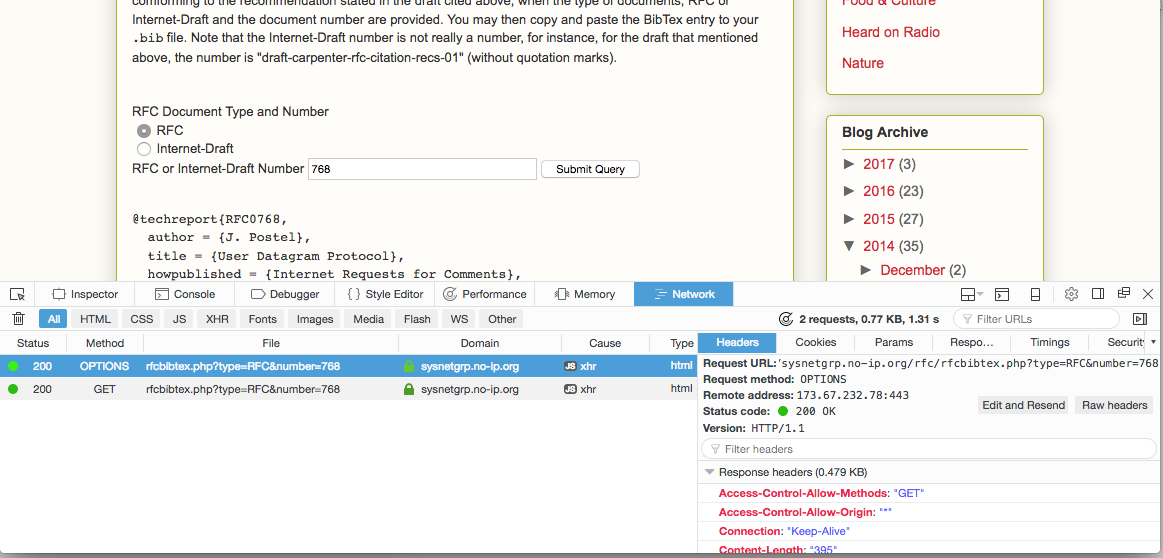
That is much more interesting, the page itself is doing a request to
https://sysnetgrp.no-ip.org
. Lets try a
curl
there and see what we get:
$ curl "https://sysnetgrp.no-ip.org/rfc/rfcbibtex.php?type=RFC&number=768"
@techreport{RFC0768,
author = {J. Postel},
title = {User Datagram Protocol},
howpublished = {Internet Requests for Comments},
type = {STD},
number = {6},
year = {1980},
month = {August},
issn = {2070-1721},
publisher = {RFC Editor},
institution = {RFC Editor},
url = {http://www.rfc-editor.org/rfc/rfc768.txt},
note = {\url{http://www.rfc-editor.org/rfc/rfc768.txt}},
}
Much better!